2. 条件随机场(CRF)模型是在2001年由Lafferty提出的判别式概率无向图学习模型,是一种用于标注和切分有序数据的条件概率模型。条件随机场是一个序列标注算法,其结合了隐马尔科夫模型和最大熵模型的特点,不仅可以考虑词语本身和上下文特征,还可以加入词典等外部特征,具有较好的实体识别效果。因而我们选择CRF做序列标注建模。
3. 长短时记忆模型(LSTM)1997年, Hochreiter等在循环神经网络的基础上提出了LSTM单元,它解决了RNN的梯度消失和长期依赖问题。LSTM基本结构由输入门(input gates)、遗忘门(forget gates)、输出门(output gates)三种结构组成,通过门结构让信息选择性地通过,实现所需信息的记忆和其他信息的遗忘。LSTM每个循环模块中有四层结构:3个sigmoid层,1个tanh层。LSTM中还存在其他隐藏状态,一般称之为细胞状态,呈水平直线贯穿隐藏层,是LSTM的关键环节,线性交互较少,易于保存信息。细胞状态无法选择性的传递信息,更新和保持细胞状态需要借助门结构(gate)来实现,门结构由一个sigmoid层和一个逐点乘积的操作组成。LSTM通过忘记门、输入门、输出门三种门结构实现对细胞信息的增加和删除。但由于LSTM神经网络的信息输入是单方向的,从而会忽略上下文信息。因此,通过双向LSTM对一个训练序列向前向后各训练一个LSTM模型,再将训练的2个模型的输出进行线性组合,使得序列中每一个节点都能获得完整的上下文信息。
4. BERT全称是来自变换器的双向编码器表征量,Jacob等人于2018年末发布的一种新型语言模型。BERT采用了双向Transfromer结构,其模型结构如下图:
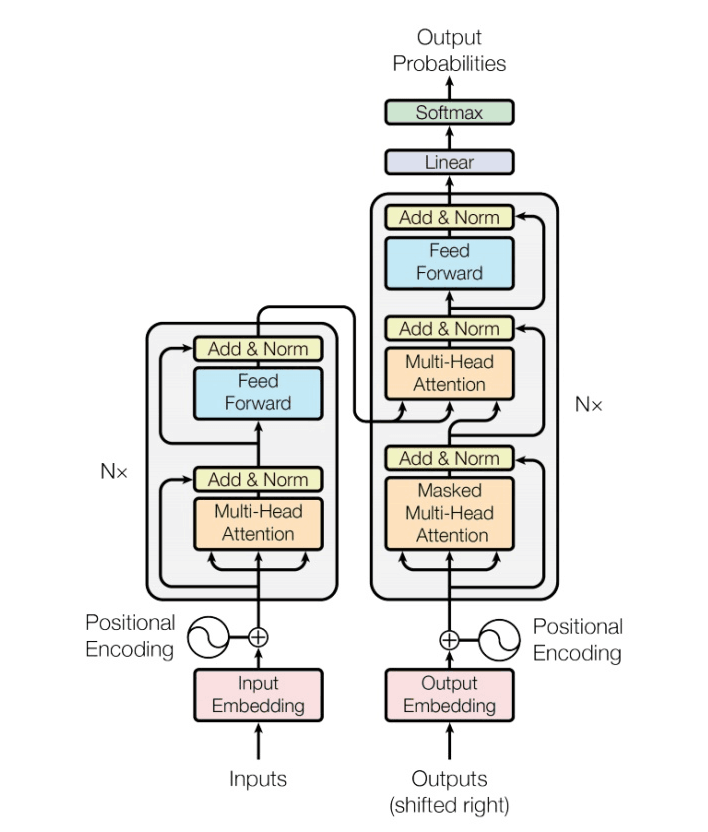
BERT模型中运用多层自注意力机制代替传统的RNN、CNN神经网络,有效的解决了自然语言处理中棘手的长期依赖问题。与其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示。因此,预训练的BERT表示可以通过一个额外的输出层进行微调,适用于广泛任务的最先进模型的构建,比如问答任务和语言推理,无需针对具体任务做大幅架构修改。BERT在多项自然语言处理任务中均取得显著效果。
参考文献:
[1] Lafferty J D, Mccallum A, Pereira FCN.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C].Eighteenth International Conference on Machine Learning.Morgan Kaufmann Publishers Inc.2001:282-289.
[2] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[3] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv:1508.01991.2015.
[4] Devlin Jacob, Chang Ming-Wei, Lee Kenton, Toutanova Kristina. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. eprint arXiv:1810.04805, 2018.
原文出处:http://corpus.njau.edu.cn/wiki/wiki/005
相关文章阅读
几个常见的汉语语料库分析
互联网上开放的中文语料库有哪些
分词介绍